Llama3.1のアーキテクチャー
Llamaとは
LlamaはMetaが開発したオープンウェイトLLMモデルです。 2024年現在ではオープンウェイトLLMモデルは多数存在し,中にはLlamaを上回る性能を持っているモデルも多数出てきているため,Llamaの存在は霞んでしまっていますが,2023年にMetaがLlamaをリリースしたことで昨今のLLMのオープンウェイト化の流れを作ったという意味で,歴史的に大きな意義のあるLLMモデルと言えます。
もし将来的にLLMを誰もが触り,手元でカスタマイズするような時代が来た場合は,おそらくマーク・ザッカーバーグは「メガテック企業の中で最もオープンウェイトLLMに貢献した人物」の一人として表彰されるのは間違いないと思います。現時点ではLLMやAI企業界隈は人材の入れ替わりも激しく3年後の状況さえ見通せませんが…。個人的にはマーク・ザッカーバーグがメタバースでの失敗を乗り越えて,LLMにおいて先駆者的な働きをしていることに驚きと称賛を覚えずにはいられません。どんだけメンタル強いんだ…。
Llamaのアーキテクチャー
さて,Llamaのアーキテクチャーに迫っていきましょう。
LlamaはMeta自身が述べている通り,2017年に公開されたTransformerアーキテクチャーに基づいて作られています。しかも「スタンダードなタイプのトランスフォーマーだ」と説明してます。
トランスフォーマーは計算効率の救世主
ここでトランスフォーマーのモデルの派生系について説明しましょう。
トランスフォーマーは,Attention is All You Need (Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin)の2017年の論文で公開された大規模言語モデルの根幹をなす設計のことを指しています。具体的にはマルチ・ヘッド・アテンションを用いることで,距離的に離れたトークン間の注意・注目度(attention)を並列計算で求めることで,従来のCNN(畳み込みニューラルネットワーク)やRNN(再帰的ニューラルネットワーク)と比較して学習効率を高めることに成功した設計を指します。2017年以降のLLMの大半はこのトランスフォーマーの設計の亜流に過ぎません。
トランスフォーマーがCNNやRNNと比較して学習効率が圧倒的に優れていたのは,並列計算ができる点でした。
従来技術であるRNNは時系列データの取り扱いに優れており,過去のデータと現在のデータを再帰的に組み合わせて計算することによって,次のデータを推測するという「推測能力・予測能力」の面では優れていましたが,逆に再帰計算をデータ1個ずつ順番に処理していく必要があることから,処理速度の面で課題がありました。端的に言うと,データが増えれば増えるほど指数関数的に計算量が増えてしまうのです。これは再帰計算の弱点そのものであり,どちらかというとCPUで実行するプログラムの延長線上にあるアーキテクチャーだったと言えるでしょう。
しかし,トランスフォーマーでは「CNNもいらない」「RNNもいらない」「注意・注目度(Attention)だけあればいい!!」= Attention is All You Needという強烈なタイトルで論文を発表し,従来技術であるCNNやRNNを使用せずにトランスフォーマーを用いて,短時間の学習で高い翻訳性能を発揮することを証明してみせました。
トランスフォーマーは複数のトークン間の注意・注目度(Attention)計算処理を細分化することに成功しました。トークン間の「注意・注目度」計算とノーマライズ計算が細分化されることで,それらを小さな計算の区分として並列計算できるようになります。また,再帰的な計算を排除したことで,データ量に対して線形に計算量は増えるものの,データ量に対して指数関数的に計算量が増えていたRNNと比較して圧倒的に計算効率が良くなりました。
この注意・注目度(Attention)計算処理の細分化の結果,データ量に対して線形に比例した規模のGPUを用意してやれば,計算時間はそのままで学習することが可能になったわけです。
極端なたとえですが,RNNだとデータ量が2倍に慣れば計算量が指数関数的に増えます。仮に4倍に増えるとしましょう。その場合,GPUを2倍用意したとしても,4倍の計算量/2倍のGPUパワー = 2倍の時間がかかってしまいます。つまり,データが2倍ならGPUは4倍用意しないと同じ時間では計算できません。それに対して,トランスフォーマーではデータに対して線形な計算量の増え方なので,データが2倍なら計算量も2倍。そのためGPUを2倍用意してやれば,2倍の計算量/2倍のGPUパワー = 1倍の時間で計算が終わります。コストパフォーマンス的に大規模化のメドがたったとういことです。
以上のようなトランスフォーマーによる計算効率革命によって,大規模学習が現実的に可能となったのです。
| ビフォー・トランスフォーマー | RNNに代表される再帰計算がボトルネック。大量のデータを計算すると時間がかかる |
| アフター・トランスフォーマー | GPUを用いて大規模学習データから効率的に学習できるようになった |
つまり,GPUを大量に用意し,大量のデータを並列計算させることで,学習のスケーリング則にしたがってLLMが驚異的な成長を遂げる下地ができたというわけです。
Llamaの公開論文では,学習データのトークン数と計算量をチャートに載せてくれていますが,まさに線形(比例)。美しい。これこそがトランスフォーマーが目指した設計の成果そのものでしょう。
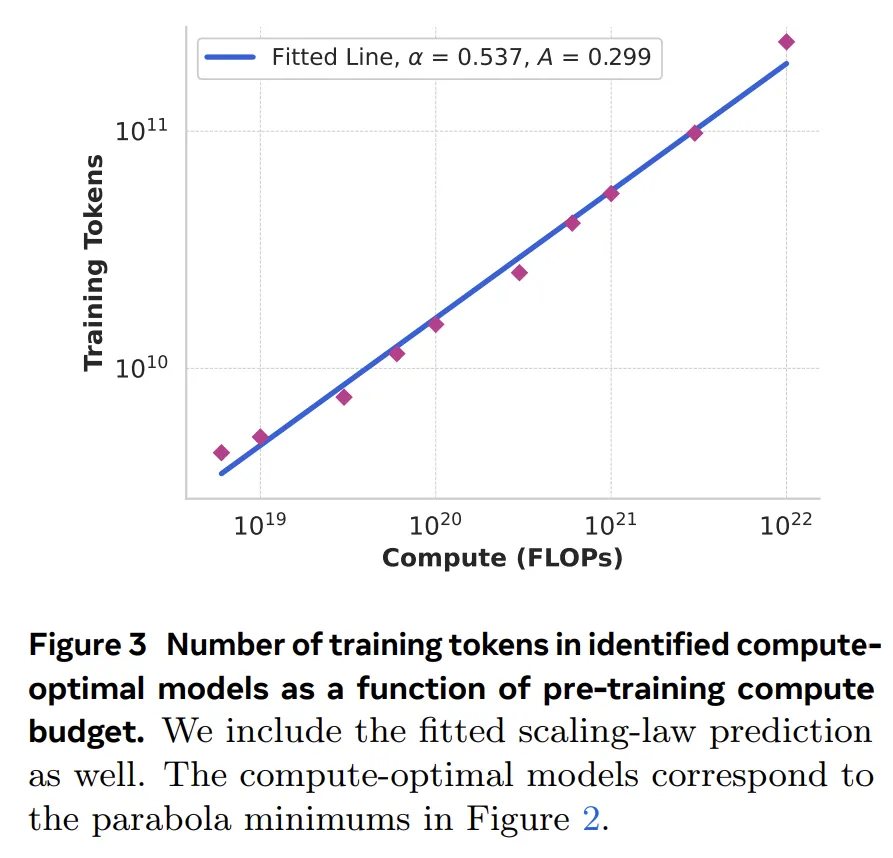
トランスフォーマーの派生系
トランスフォーマーはAshish Vaswaniらが設計した元祖である「Dense Transformer」以外にもいくつかのモデルが提案されて実用化されています。
| Dense Transformer | 用意した全てのパラメーターを用いて「注意・注目度」計算を行うスタンダードモデル。「注意・注目度」計算には全てのパラメーターを用いるため精度は高いものの,パラメーター数に比例して推論時の計算コストが嵩む。品質重視モデルとみなすことができます。 |
| Mixture of Expert Transformer | MoEとも略されるマルチ・エキスパートモデル。入力されたトークンをルーターで処理し,どのエキスパートで処理するかを入口で決めてしまい,実際の「注意・注目度」計算処理は選択された一つのエキスパートが行うという節約モデル。パラメーター数が大きくなったとしても推論処理の際には高速で実行可能な点に特徴がある。推論コスト節約モデルとみなすことができます。 |
| Hybrid MoE Transformer | MoEモデルだと一つのエキスパートの取り扱っているパラメーターでのみ計算を行うためshつ力のクオリティが落ちる懸念があり,その場合に適度にDenseモデルとデータのやり取りを行うことによって,出力品質の低下を防ごうとしたモデルです。DenseモデルとMoEモデルのいいとこ取りというイメージです。 |
Dense Transformer
- Llama系列:Llama, Llama2, Llama3, Llama3.1, Llama3.2はどれもDense Transformerの設計に基づいており,これらのバージョンの違いは純粋に学習データ品質の向上と学習データのサイズの拡大によるものだとMetaは説明しています。Metaの公開論文は正直で素晴らしいですね。
- Gemma系列: GoogleのGemma, GeminiもスタンダードなDense Transformerの派生型
- Qwen系列
- DeepSeek Coder/Chat系列
- Comand-R系列
MoE Transformer
- DeepSeek MoE: Deepseekでは[DeepSeekMoE:(https://arxiv.org/html/2401.06066v1)と呼ばれるMoEモデルを公開しています。論文の最初に出てくる図はちょっと作為的で引いてしまいますが…。アクティブ化されているパラメーター数が少なくてもモデル自体はVRAMに載せないといけないので,実際のパラメーターはこの10倍じゃない?みたいなツッコミをしたくなってしまいます。もちろん,推論計算自体が高速なのは間違いないと思うので,うまく適用できるジャンルにおいては高速で優秀な能力を発揮できるとは思いますが。
- Phi3.5-MoE: Microsoftが公開してるMoEモデルです。
- GRIN-MoE: これもMicrosoftが公開しているMoEモデルです。
MoEに興味のある方はHuggingFaceが公開してるブログ記事Mixture of Experts Explainedをご覧ください。MoEのアイデア自体は1991年にまでさかのぼり,当時から推論計算コスト削減のためにアイデアがあったことがうかがえます。この30年以上前のアイデアがTransformerに適用されたというわけですね。
Hybrid MoE Transformer
- Arctic: Snowflake社が公開しているエンタープライズ向けのLLMモデルです。かなり計算量を節約できることを特徴としています。興味のある方は試してみてください。HuggigFaceに公開されているためHuggingface Transformerの4.39.0以降では動かせます。
Llama3のアーキテクチャー
だいぶトランスフォーマーの説明で脱線してしまいましたが,Llamaのアーキテクチャーに戻ります。
Llama3では以下の設計になっています。
| 8B | 70B | 405B | |
| Layers | 32 | 80 | 126 |
| Model Dimension | 4,096 | 8192 | 16,384 |
| FFN Dimension | 6,144 | 12,288 | 20,480 |
| Attention Heads | 32 | 64 | 128 |
| Key/Value Heads | 8 | 8 | 8 |
| Peak Learning Rate | 3 × 10−4 | 1.5 × 10−4 | 8 × 10−5 |
| Activation Function | SwiGLU | ||
| Vocabulary Size | 128,000(English: 100,000 token + Non-English: 28,000) | ||
| Positional Embeddings | RoPE (θ = 500, 000) |
その他
- トークナイザー: tiktoken (Mistralなど各社で用いられている高速トークナイザー)
- トークン言語比率: 英語100kトークン, 非英語28kトークンで英語学習データが7割を占める
8B, 70B, 405Bと学習のスケールを増大させた結果,以下のチャートにあるように今のところはスケーリング則にしたがってLLMは賢くなっています。
- 学習することによってValidation Lossが減少している = すなわち賢くなっている。
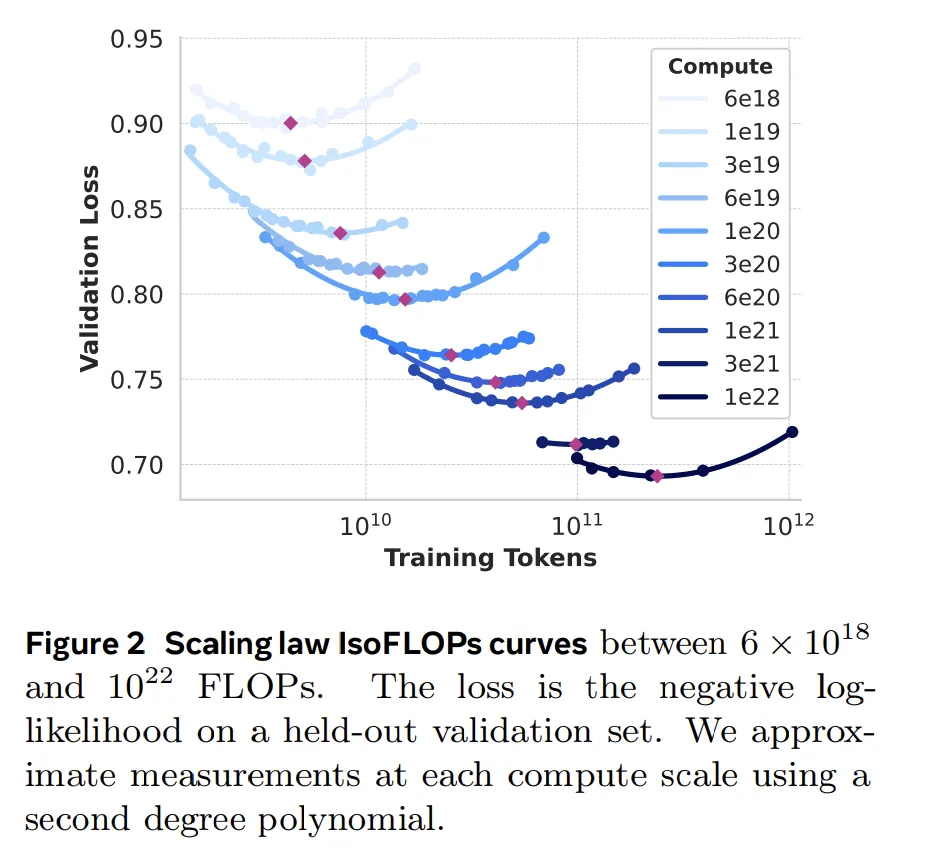
以上でLlama3.1までのLlamaアーキテクチャーの説明を終わります。 Llamaはオープンウェイト界の巨人であり,今後も膨大な学習データを用いてスタンダードなトランスフォーマーがどこまで進化できるか,極限を探ってくれると思います。ザッカーバーグは猛烈にNVidiaのGPUサーバー(H100や次世代のH200)を買い集めていますし,スケーリング則がまだまだ有効であるとわかっているうちは各社金に物を言わせてひたすら学習規模を増やしていくでしょう。
トランスフォーマーの誕生によって,現時点では学習データに対して計算量が線形にしか増えないのが保証されており,しかも学習データを増やせば賢くなることも分かっている。2017年以降はチキンレースですが,成功が約束されたチキンレースに各社が参戦しているというのが実態です。 自社がやらないなら確実に他社がやると分かっている。 だからこそ,利益が出ようと出まいと,他社より先んじて優秀なLLM, AIを開発し,さらにそのLLM, AIを用いて新規技術や新発見を自社特許で囲い込んでしまいたい。
ここまで成功が保証されている大規模開発というのは珍しいです。 当たりハズレという意味では,2017年から2024年夏までは「大量に学習させたもの勝ち」だったわけですから。 当面の間はどの会社も撤退することは考えられません。
今後数年間でどこまでスケーリング則が成立するか,ワクワクしながら見守りましょう。